在今天,我們要介紹一個在預訓練模型中相當經典的模型。基本上,我們可以認為這個模型就是一個Transformer模型,但它的預訓練策略非常強大,使其成為2018年最強大的模型之一,甚至到現在仍然具備強大的能力。話不多說,讓我們來看看這個模型為何如此強大吧。
BERT(Bidirectional Encoder Representations from Transformers)是2018年由Google提出的,其模型參數設計與原始的Transformer模型並未有太多的改動,而最大的改動是它只保留了Transformer的Encoder部分。這麼做的原因是如果我們訓練一個完整的Encoder-Decoder模型,其架構會變得非常複雜,而BERT這個模型基本上就是一個專門的分類模型,因此不需要Decoder生成的部分。
BERT與Transformer不同的關鍵特徵在於,它是一個**雙向(bidirectional)**的模型,能同時從左到右和從右到左建模文本上下文。不過,這時你可能會想,Transformer不是依靠將位置信息嵌入到Embedding層中來理解位置信息的嗎?那為什麼還會有單向與雙向之分呢?現在我們來看看BERT所進行的兩個預訓練策略吧。
BERT與Transformer不同的關鍵特徵在於,它是一個**雙向(bidirectional)**的模型,能同時從左到右和從右到左建模文本上下文。不過,這時你可能會想,Transformer不是依靠將位置信息嵌入到Embedding層中來理解位置信息的嗎?這裡的區別在於,傳統的Transformer模型通常是在在編碼和解碼過程中依次處理文本,而BERT則能同時考慮整個句子的上下文,從而在理解和生成文本時提供更豐富的語義信息。現在我們來看看BERT所進行的兩個預訓練策略吧。
這讓我想起在Transformer中使用的src_mask參數。這個參數作用類似於Decoder中的tgt_mask參數,目的是遮蔽未來的信息。因此這種設計使我們有了單向的Transformer。然而BERT的雙向模型不僅限於此,BERT的雙向特性體現在它的MLM( Masked Language Model)策略中。MLM,即「隱藏語言模型」策略,是通過隱藏部分文本並讓模型從數萬個Token中找出正確的Token來實現的。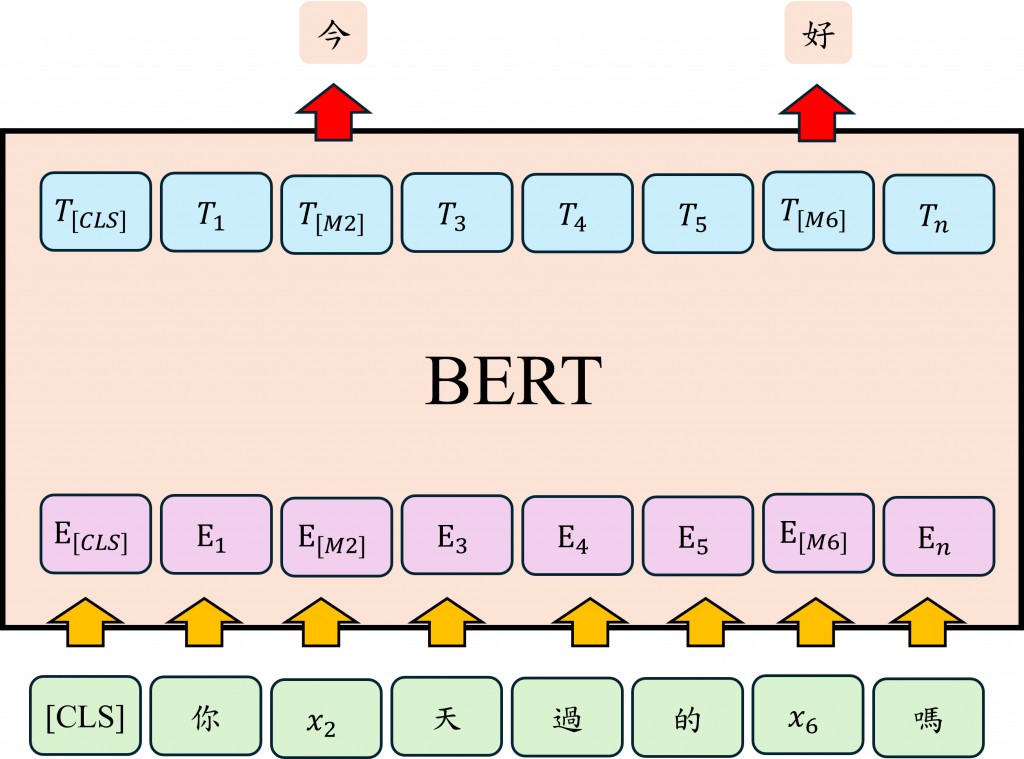
例如: 我今天吃了[MASK],很好吃,BERT會隨機將「吃了」後面的詞遮蔽,並要求模型根據上下文來預測這個被遮蔽的詞是什麼。與單向模型不同,BERT不僅會考慮前文「我今天吃了」來做出預測,還能利用後文來幫助確定遮蔽的詞。這種雙向語境理解能力是BERT能更精準進行語義預測的關鍵,而能有這種交互式的運算也要歸功於Self-Attention的模型架構與其能將整段文字中的每個詞彙都相互關聯計算的能力。
在BERT的MLM任務中,其實並不會每次都把遮蔽的文字用[MASK]代替,偶爾會使用真實的隨機Token進行替換與猜測。這是因為在我們實際使用時,不會出現[MASK]這一標籤。為了減少上下游任務之間的差異,採用真實的隨機Token的方式,讓模型在預訓練階段就能夠熟悉沒有[MASK]的推理狀態。這麼做的目的是讓模型在實際應用時更加靈活和準確。當模型學習到即使沒有[MASK]標籤也能準確預測上下文時,它在面對各種不同類型的文本時表現會更好。因此使用隨機Token替換部分遮蔽的文字,是一種有效的訓練策略。
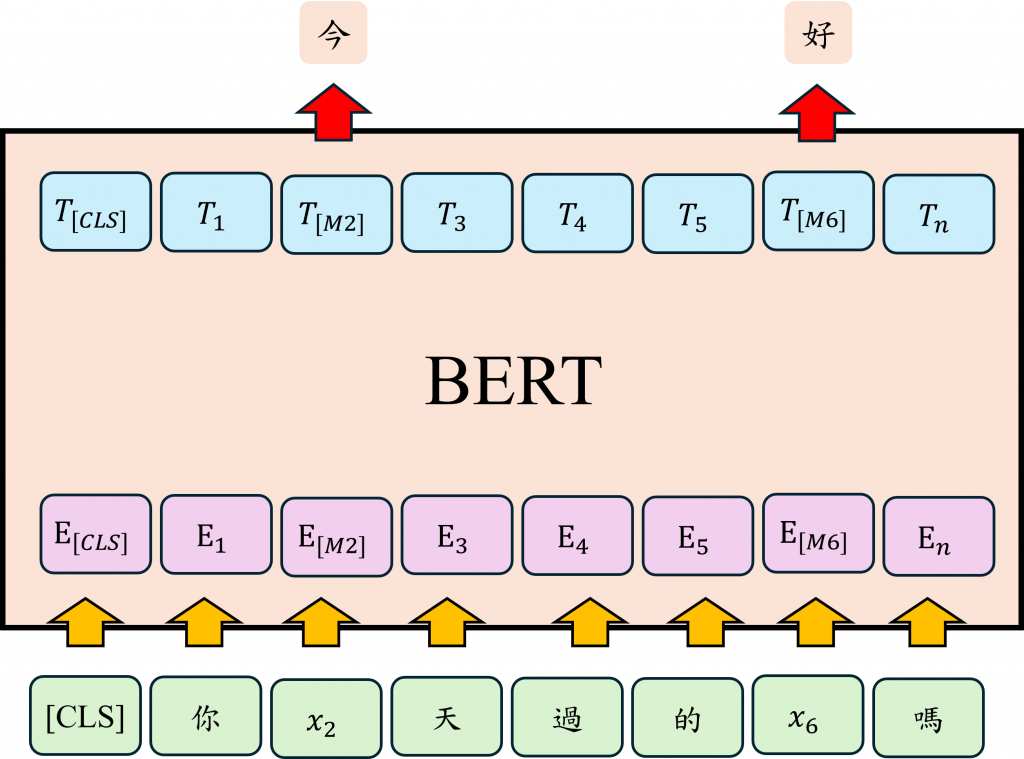
而BERT也有另一個訓練策略,就是NSP(Next Sentence Prediction)。這個策略的目的是幫助模型理解句子與句子之間的邏輯關係,這在處理例如問答系統或文本推理等任務時非常重要。這個方法是給BERT兩個句子,然後模型需要判斷第二個句子是否真的是緊接在第一個句子之後的合理連續句子。在預訓練階段,BERT會隨機選取一些句對,其中一半的句對是連續的,另一半則是沒有邏輯連貫性的,並讓模型學習判斷這兩個句子是否相關。該任務也在某些程度上強化了BERT模型對於MLM的任務能力,因為該任務更能讓模型學會這些上下文之間的關聯性。
而只使用了這兩個策略,BERT就在理解文本上下文時取得了多個資料集的SOTA(State-of-the-Art)成績。這兩個策略讓模型與以往的時間序列模型或使用遮罩的Transformer不同,不僅僅是從左向右或從右向左解讀文本,而是同時考慮兩個方向,讓BERT到現在還是在自然語言處理上非常熱門的模型。
在前面的章節中我們在撰寫程式碼時都是使用了BERT的Tokenizer進行模型的訓練,而這時如果你有嘗試還原文字時,你會發現[CLS]、[SEP]、[PAD],這三個標籤,以下讓我們看看這三個特殊Token的功能:
[CLS] (Classification): 這個Token用於句子的開頭,通知模型這是一個新句子的開始,類似我們之前學到的<SOS>或<BOS>,而三個特殊Token它們的功能完全相同只不過在Seq2Seq會叫做<SOS>、Transformer會叫他<BOS>,BERT則叫做[CLS]。
然而在BERT中有一個比較特殊的部分,由於Transformer在進行Attention後,每個輸出都包含整個句子的完整訊息。因此為了避免這些輸出訊息過多,BERT在進行分類時只會使用[CLS]這個序列的對應輸出,將其提供給線性分類器進行分類,讓[CLS]能夠經過訓練後代表了整個句子的語意。
而[SEP] (Separation)通常用來分割不同的句子,尤其是 BERT 在進行問答系統、文字相似度比對、邏輯性判斷時,就會在兩句之間加入[SEP] Token,例如:[CLS]今天天氣如何?[SEP]很好[SEP],像是這樣的操作,讓模型能夠更好的理解其上下文。
最後就是[PAD] (Padding)這一個Token其目的就是用於填充的這一點我們應該很熟悉了,不過其時BERT還有[MASK]這一個特殊Token,這一個Token只會出現在MLM任務中,因此我們在實際上訓練時並不會使用到該特殊Token。
BERT模型的Embedding與我們之前學習到的Embedding有所不同,它有三層Embedding層。首先,BERT會經過Token Embeddings的處理,這個過程與我們先前學習的Embedding完全相同,就是將每個Token映射到對應的詞嵌入中。由於BERT可以同時處理兩個句子的輸入,所以會使用[SEP]標記來區分句子。每個標記會被分配一個片段嵌入,用來指示它是屬於第一句(A句子)還是第二句(B句子)。這樣,我們就能將剛剛完成映射的詞嵌入分別添加到相應的Segment Embedding中。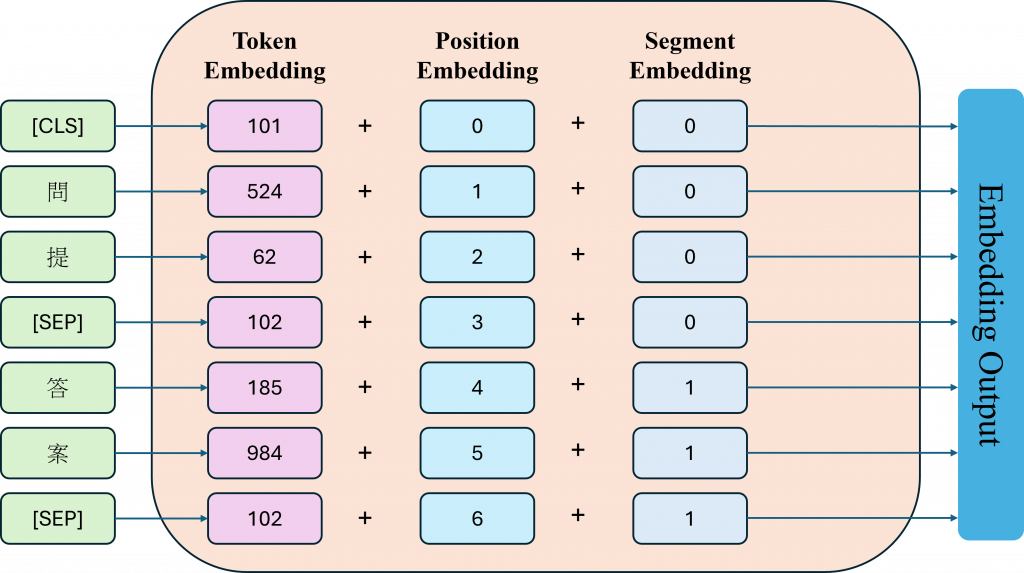
另外由於Transformer模型本身不具備位置信息,BERT採用了Position Embeddings,而不是Transformer中的絕對Positional Encoding。這使得每個Token能夠學習到對應的相對位置。最終,這三個Embedding會被相加,形成最終的詞嵌入表示。這些詞嵌入會被傳遞到Transformer中的多層編碼器,進行進一步的語義表示學習。
在這次介紹中,我們講到了BERT模型的強大預訓練策略,以及其中的創新,包括MLM(遮蔽語言模型)和NSP(下一句預測)這兩個策略。這兩個策略看似簡單,但實際上效果非常強大,能夠使BERT的雙向性在同時考慮文本的上下文方面超越了單向模型的限制。此外BERT還使用了特殊的[CLS]、[SEP]等Token及三層嵌入的設計,進一步提升了語言理解和位置資訊捕捉的能力。當然除了上述這些特點,BERT還依托於龐大的資料集,才得以在2018年成為最強的模型之一。而在本次內容中可以發現我們並沒有數學式,因為在BERT中其實也沒什麼特別的數學是好說,這一現象其實也出現在後續的預訓練模型中,因為其概念本質上就是一個Transformer。

